How to prevent website crashes in 10 simple steps

Website crashes are a constant threat to any business or organization with an online presence. But they’re also (mostly) preventable. Discover why websites crash and the key strategies the world’s biggest companies use to prevent website crashes and build reliable and resilient sites.
*If your website is down right now because of overwhelming traffic, we can help. Implement Queue-it’s virtual waiting room in under an hour to regain control of your site performance.*
Table of contents
- Why you need a website crash prevention plan
- Why websites crash
- 10 steps to prevent website crashes
- Set up detailed, proactive monitoring
- Run performance & load tests
- Identify & eliminate bottlenecks
- Optimize performance
- Eliminate single points of failure
- Configure autoscaling
- Control traffic with a virtual waiting room
- Downgrade the user experience
- Block bad traffic and bots
- Improve & automate processes
- Summary: Crash-proof your website
A one-hour outage cost Amazon an estimated $34 million in sales in 2021.
A 20-minute crash during 2021's Singles' Day sales cost Alibaba billions.
Facebook's 2021 outage cost Meta nearly $100 million in revenue.
Website crashes affect everyone from small businesses to governments to retail giants. There is no “too big to fail” in the world of websites. Amazon, Apple, Facebook, the IRS, Google—they’ve all been taken offline for one reason or another.
In the past 3 years, 94% of enterprises experienced at least one IT outage. The average number of outages per year for these enterprises was 19. And more than half of surveyed IT leaders say the incidences of crashes are increasing.
There is no "too big to fail" in the world of websites.
Website crashes decimate your revenue, harm your reputation, break down customer loyalty, hurt employee productivity, and spike operational costs:
- 91% of enterprises report downtime costs exceeding $300,000 per hour.
- Costs are up to 16x higher for companies that have frequent outages compared to those with fewer instances of downtime.
Putting the steps in place to prevent website crashes and speed up site recovery may not be the most exciting project, but it’s one that will pay dividends.
A website crash prevention (and recovery) plan will save your business or organization money, save your colleagues time, and save your site visitors frustration and distrust.
RELATED: The Cost of Downtime: IT Outages, Brownouts & Your Bottom Line
"Downtime of even one to two seconds can be very costly. When you multiply that by 60,000-100,000 people, that adds up. Whenever anyone else is involved as well, influencers or another brand, we don't want to affect how their audiences view them."
ALEX WAKIM, DIRECTOR OF OPERATIONS & BUSINESS DEVELOPMENT
You can’t solve a problem you don’t understand. So to prevent website crashes, you first need to understand why they occur. There are many reasons why a website can crash. These include:
- Broken/bad code: When bad or broken code is deployed, breaking part of the website.
- Plugin errors: When a plugin/extension causes issues on your site—either due to high traffic, bugs, or failure to update software.
- Issues with updates: When updates are made that are partial (meaning one part of the site is updated, but not another), or buggy, or break some key feature of your site.
- Server or hosting provider errors & outages: When cloud hosting providers or other critical service providers experiences outages.
- Web traffic spikes: When surges in web traffic overwhelm your infrastructure and/or its bottlenecks.
- Expired domain names: When a site owner fails to renew their domain name.
- Malicious cyberattacks: When bad actors intentionally crash your site to exploit vulnerabilities or sabotage your business or organization.
- Network failure: When a component or connection in the site’s network goes offline, becomes disconnected, or otherwise fails (i.e. a routing issue, a cable break, or router going offline).
The three most common reasons websites crash—according to LogicMonitor’s global survey of IT professionals—are network failure, web traffic spikes, and broken/bad code (human error).
Some of these causes of site crashes are easier and cheaper to prevent than others.
Preventing an expired domain name, for example, is as easy as ensuring your domain hosting plan automatically renews. But it’s almost impossible to safeguard against some third-party service provider outages—cloud computing companies are called “the backbone of the internet” for good reason.
More than half of surveyed IT professionals say they consider IT outages avoidable. Why? Because proven strategies exist that dramatically minimize the risk and mitigate the impact of a website crash. Because major companies and organizations use these strategies to avoid website crashes every single day.
RELATED: The 8 Reasons Why Websites Crash & 20+ Site Crash Examples
Website monitoring is your site’s version of a smoke detector. It won’t put out the fire that is a website crash, but it’ll tell you something’s burning and help you keep it from getting out of control.
Website monitoring is a testing process that performs routine health checks on your site and reports on things like performance, availability, security, and functionality.
A massive 74% of global IT teams rely on proactive monitoring to detect and mitigate outages. LogicMonitor found the IT teams with proactive monitoring endured the fewest outages of all those surveyed.
There are several types of website monitoring, often packaged together:
- Security & malware monitoring routinely runs malware and security checks to identify vulnerabilities and notify you if there are signs of malicious behavior.
- Network monitoring keeps tabs on the behind-the-scenes components that ensure your website runs, providing information like server uptime, response time, and bandwidth utilization.
- Activity monitoring gives you an activity log that keeps track of everything that happens on your site, like edited pages and updates to plugins—so if an update takes your site offline you can identify what it was and when it happened.
You can likely already see how these monitoring services can help prevent and mitigate many of the causes of site crashes outlined above:
- Security & malware monitoring helps prevent website crashes due to malicious attacks by identifying vulnerabilities.
- Network monitoring helps you identify and act on slow response times and downtime proactively—so you know your website is struggling before your customers do.
- Activity monitoring helps identify the code or plugin changes (human errors, update issues, and bad code) that caused your website to break, letting you quickly identify and fix the problem.
In short, website monitoring alerts you to failures in real-time and provides detailed insights into your site performance. It can be configured to notify you moments before a website is about to crash, giving you a chance to act and prevent it.
And if your site does crash, website monitoring gives you important insights into your application that allow you to conduct a root cause analysis based on facts, not guesswork. An accurate understanding of the root failure will allow you to optimize your system for the future.
At Queue-it we use Pingdom for our uptime monitoring, which identifies any and all disruptions or outages that occur among our services. It runs a check on each of our services and data centers every minute, allowing us to keep tabs and records on uptime and response time by country.
Performance testing is like a dress rehearsal for your site or app. It lets you measure the speed, scalability, and reliability of your site in a test environment.
If you know your system works, performance tests ask the questions: “How well does it work? And does it work at scale?”
There are many types of performance tests for websites, including:
- Load tests: which apply an expected (or slightly extreme) amount of load to your system to determine performance during periods of heavy usage.
- Stress tests: which apply increasing amounts of load to your system until it breaks to simulate system overload and determine recovery time and system vulnerabilities.
- Spike tests: which apply load in short, sudden spikes, to simulate real-world web traffic spikes.
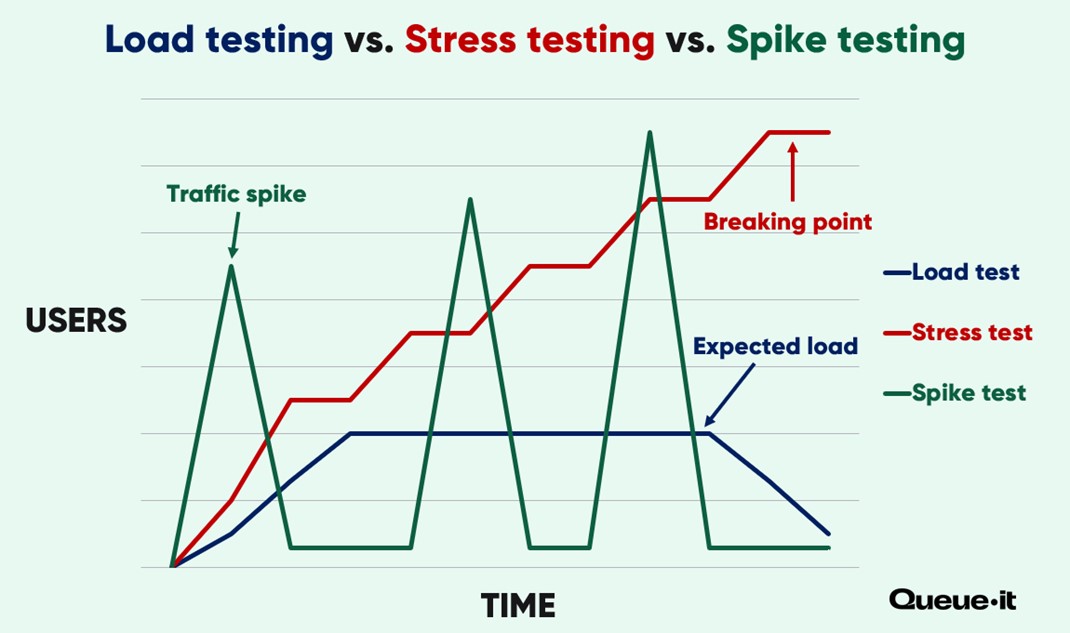
The biggest websites and most popular services in the world run many types of performance tests for various purposes. But for most businesses and organizations, load tests are enough to prepare you for high traffic and help prevent website crashes.
Load tests are important for any system that has fluctuating and unpredictable levels of load (traffic, requests, actions). They let businesses and organizations simulate different levels of load in a controlled environment, so they don’t experience crashes, errors, or slowdowns during popular events like Black Friday, tax time, or a major concert onsale.
By applying load to your site in a test environment, you can safely identify performance bottlenecks and get the information you need to optimize your systems and handle major traffic with confidence.
RELATED: Everything You Need to Know About Load Testing
57% of organizations run performance and/or load tests at every sprint, and 95% commit to testing annually, meaning just 5% of IT professionals “never” run load or performance tests.
Load testing can also help prevent website crashes caused by human error and bad code by spotlighting code that works fine with a few users, but can't scale in production.
By running load tests on all new releases, major changes, and new or updated plugins, you can identify these errors before your customers do. That’s why 63% of enterprise IT leaders execute performance and/or load tests on all new releases.
Just 5% of IT professionals never run performance tests—a group you don't want to be a part of.
Load testing isn’t a one-and-done step, though. It’s a process.
Each test is likely to reveal new bottlenecks that need fixing. Adding or changing code also requires new load testing. Plus, it’s easy to run load tests that miss key bottlenecks by failing to simulate true user behavior.
LeMieux, for example, load tested their site ahead of their big Black Friday sale. They determined their site capacity and used a virtual waiting room to control the flow of traffic and keep it below the threshold they’d determined.
But on the morning of their sale, they discovered slowdowns related to bottlenecks in their site search and filter features. The load testing of the site had not simulated true user behavior, focusing on volume of traffic and orders, rather than the resource-intensive dynamic search.
"We believed previous problems were caused by volume of people using the site. But it’s so important to understand how they interact with the site and therefore the amount of queries that go back to the servers."
Jodie Bratchell, Ecommerce & Digital Platforms Administrator
This is a valuable lesson to keep in mind for your load tests. You need to understand how customers act on your site and ensure you replicate that behavior under load.
Fortunately for LeMieux, with Queue-it’s virtual waiting room in place, they could lower the outflow of visitors from queue to website in real-time and quickly resolve the issue.
Also, be sure to notify your hosting provider you’re running the load test. Otherwise, it could look like an unwanted DDoS attack. Many providers consider an unauthorized load test a violation of terms of service.
RELATED: Everything You Need to Know About Website Crashes: Causes, Prevention & Examples
There’s a reason this list doesn’t just have one step that says, “pay your cloud service provider more and scale up your servers.” Increasing the computing power of your servers is important, but your website functions based on dozens or hundreds of composite parts—many of which can’t scale endlessly.
When Canadian Health Center NLCHI was facing massive traffic for vaccinations, for example, they thought scaling their servers on AWS would help. But, as Andrew Roberts, the Director of Solution Development and Support told us, “this just brought the bottleneck from the frontend to the backend.”
That’s why you need to understand the distinction between overall capacity and operational capacity.
Think of your website as a restaurant. The overall capacity of the restaurant (how many you can fit into the room) might be 100 people. But its operational capacity is limited by other factors—like the number of waiters and cooks working, the number of stoves you have, your cash registers and bathrooms.
These limiting factors—the waiters, the stoves, the cash registers—are your restaurant’s bottlenecks. They’re what’s keeping you from taking on more customers while maintaining performance—not the size of your restaurant.
So when you’re deciding how many people to let into your restaurant, you can’t just look at the size of the room (your overall capacity), you need to look at how many people you can comfortably serve (your operational capacity).
The same applies to websites. Scaling up your servers and implementing a CDN may mean you can handle 10,000 visitors sitting on your home page. But this isn’t the number you need to focus on. It’s the 100 visitors per minute that are hitting your checkout or dynamic search features.
It’s typically these bottlenecks that cause sites to crash. Common site bottlenecks include:
- Payment gateways
- Database locks & queries (e.g. logins, updating inventory databases)
- Building cart objects (add to cart or checkout processes, tax calculation services, address autofill)
- Third-party service providers (authentication services, fraud services)
- Site plugins
- Synchronous transactions (e.g. updating inventory databases while processing orders and payments)
- Dynamic content (e.g., recommendation engines, dynamic search & filters)
To increase your operational capacity, you need to identify and optimize or eliminate these bottlenecks. This is precisely why load testing and monitoring are so important—they’ll point you to where the problems are.
If you’ve already experienced a crash, and you have detailed monitoring set up, you should be able to run a root cause analysis and determine if any of the above bottlenecks were at fault. If you haven’t yet crashed or had issues, a load test will work similarly to point you towards your site’s bottlenecks.
RELATED: 2 Hazardous Bottlenecks That Can Crash Your Ecommerce Website
Bottlenecks like these are the areas you need to focus on if you want to handle more traffic. Understanding your bottlenecks is understanding that you don’t need a bigger restaurant; you need to hire more staff.
Improving different bottlenecks will require different actions. For example, if you’re worried a third-party service or payment provider won’t be able to handle your traffic, you can contact them and ask about their throughput (how many users they can handle passing through their system per minute) and whether you they can improve it. You can also review your service level agreement (SLA) with the service provider, as most businesses make commitments to being able to handle a certain amount of traffic via an SLA.
In the next step, we’ll cover some basic ways you can improve the performance of almost every website and take some of the load off its bottlenecks.
The most broadly applicable way to get more performance out of your site is to optimize the content you’re serving visitors.
Returning to the restaurant analogy, you need your menu to be less complex. You need to offer simple drinks and a breadbasket you can quickly serve without putting much strain on your staff.
Essentially, you want to identify heavy database requests and limit their number, size, and complexity. Some simple tactics for this include:
- Use a content distribution network(CDN), which responds to browser requests for your static content, like your home page and product images. This frees up your servers to focus on dynamic content, like your Add to Cart calls and checkout flows.
- Compress images and upload them at their intended display size. Use lazy loading to load media on demand, rather than all at once. Visitors perceive sites that load this way as faster, even if the actual load times are comparatively slow.
- Minimize the use of plugins where possible. They can quickly become out of date, and may not always maintain compatibility with your CMS or ecommerce platform.
RELATED: Optimize Your Website Performance with These 11 Expert Tips
Why are modern airplanes built with 4 engines when they typically only need one to fly? Because an airplane crash is an avoid-at-all-cost problem. Extra engines are just one of many redundant systems airplanes are built with, so that if any system fails in-flight, another can take over and the plane can maintain functionality.
If you’re serious about preventing website crashes, you need to think about your website in the same way. You need to eliminate single points of failure (SPOF).
To identify SPOFs, think of the services your website couldn’t run without (cloud hosting, payment providers, data centers, etc.). These are your airplane engines. To eliminate these SPOFs, you need to build additional redundant engines. This could involve:
- Hosting your site across multiple, distributed data centers to avoid it going totally offline or completely losing access.
- Establishing second payment service provider to switch to in the event of payment gateway failure.
- Using server clustering technology to run a duplicate copy of the application on a second server.
- Ensuring you have redundant hardware, such as additional cable connections that can be used in the event of a cable break.
While this is an expensive process, it’ll help you pivot quickly if one of your system dependencies fails. It’s also one of the only ways you can prevent crashes due to network failure.
Eliminating SPOFs is about reducing the “blast radius” of the issues that can cause your website to crash. Blast radius is a term used in cloud computing to describe the reach of a problem.
If a configuration change takes your whole site or service offline for all users everywhere, for example, it has a large blast radius.
By reducing your SPOFs, you can ideally limit the blast radius of the erroneous change—keeping its impact contained to a small subset of users or a single region.
At Queue-it, we avoid SPOFs by hosting our service across 3 availability zones for each region we’re based in (North America, Europe, and Asia-Pacific). Think of these like having 3 engines in different parts of an airplane. In the (unlikely) event of a failure in 2 availability zones, Queue-it can still operate on the third.
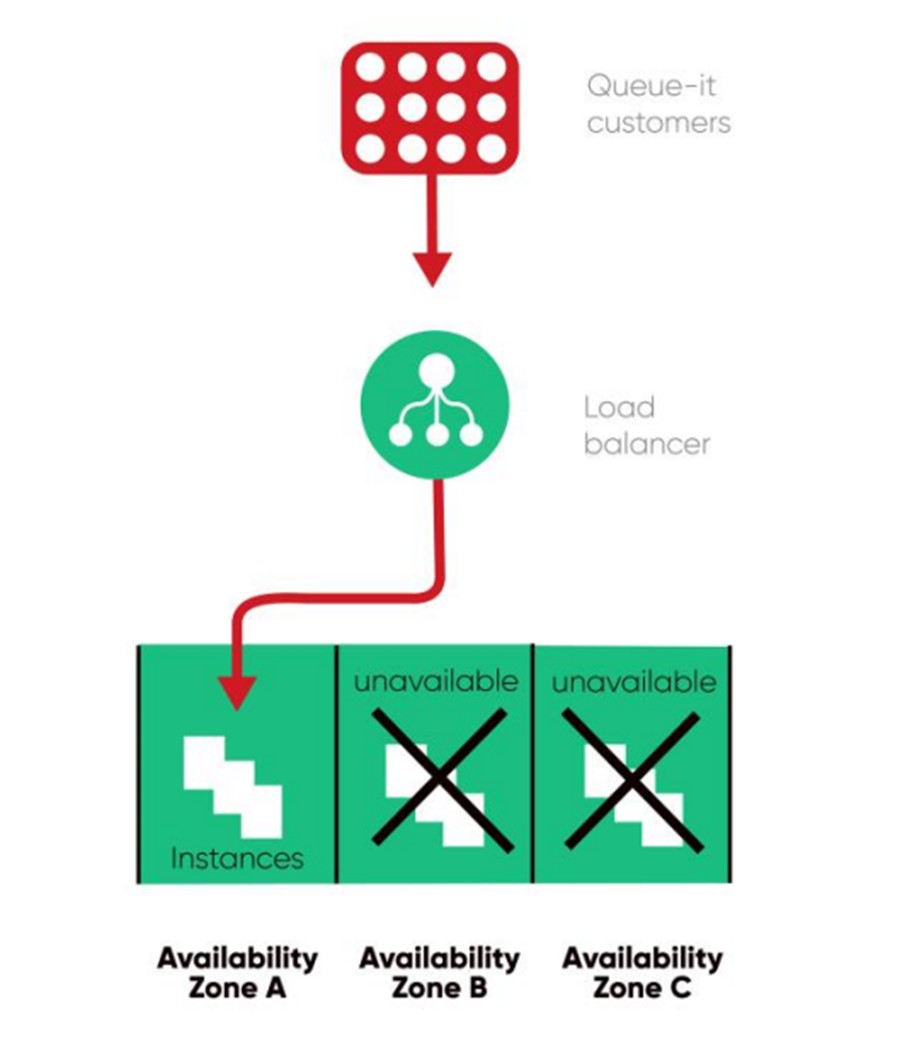
As Queue-it works with major companies on website crash prevention, high availability is prioritized over the reduction of operational costs. You can learn more about how Queue-it ensures extremely high availability in our High Availability Whitepaper.
Autoscaling is critical for any business dealing with fluctuating traffic levels. It enables your servers to automatically adjust their computing power based on current load.
With autoscaling, your server capacity can temporarily expand and shrink according to your needs. This reduces the need to make predictions about traffic levels and makes your system more elastic and reactive.
Autoscaling saves money on the quiet days. And preserves performance on the big ones.
Or at least that’s the hope.
While this is what autoscaling does, it’s a bit more complicated than that. And as anyone who hosts a high traffic website knows, autoscaling isn’t the “cure-all” it sounds like.
RELATED: Autoscaling Explained: Why Scaling Your Site is So Hard
There are three main reasons autoscaling is only a partial solution to traffic-induced crashes:
- Autoscaling is complex: It's extremely difficult and sometimes impossible to automatically scale all components of your tech stack. This means that even if you scale your servers, traffic still overloads bottlenecks like databases, inventory management systems, third-party features like payment gateways, or performance-intensive features like dynamic search or a “recommended for you” panel.
- Autoscaling is reactive: Because traffic levels are hard to predict and autoscaling takes time to kick in, your systems likely won’t be ready in the critical moment they’re needed.
- Autoscaling is expensive: Most websites are built to perform under their usual amount of traffic. Building a website that can handle huge traffic peaks that only come a few times a year is like buying a house with 10 extra bedrooms and bathrooms because your family comes to visit sometimes—it’s expensive, impractical, and unnecessary.
The video below explains in simple terms what autoscaling is and its importance, but why it hasn't made website crashes a thing of the past.
We use autoscaling at Queue-it, as do major companies like Walmart, Ticketmaster, and Amazon. It’s a great tool for increasing capacity while reducing costs. But you need to be clear about what you expect from autoscaling.
In our experience, autoscaling can take between 2 and 5 minutes to get new instances (more server capacity) up and running. When we’re dealing with customers who get hundreds of thousands of new users per minute, this simply isn’t enough. That’s why we work in tight collaboration with customers and pre-scale ahead of large events. With pre-scaling, Queue-it has run load tests that handle up to 1 million users per minute with not a single 503 error response.
For most websites, however, the shortcomings of autoscaling are less about the capacity of website servers, and more about their bottlenecks and the on-site behavior of customers. So when autoscaling isn’t enough, the solution is to manage and control the traffic.
"Not all components of a technical stack can scale automatically, sometimes the tech part of some components cannot react as fast as the traffic is coming. We have campaigns that start at a precise hour … and in less than 10 seconds, you have all the traffic coming at the same time. Driving this kind of autoscaling is not trivial."
Alexandre Branquart, CTO/CIO
What do brick-and-mortar stores do when capacity is reached? How do venues deal with bottlenecks like ticket and ID checking? How do department stores deal with thousands of Black Friday customers trying to get into their store at once?
In all these scenarios, the flow of people into the stores/venues (inflow) is managed with a queue.
The same principle applies to websites. You can reliably prevent website crashes due to high traffic by controlling the flow of visitors to your site. And you can reliably control the flow of site visitors with a virtual queue.
A virtual queue (AKA a virtual waiting room) lets you keep visitor levels exactly where your site or app performs best. This ensures your overall capacity isn’t exceeded, but more importantly, it ensures the distribution of traffic to avoid overwhelming your bottlenecks—meaning your operational capacity isn’t exceeded either.
A virtual waiting room manages and controls what no other crash prevention strategy can: the customers.
In high-demand situations, the virtual waiting room solution redirects online visitors to a customizable waiting room using an HTTP 302 redirect. Visitors experience a short wait, then are flowed back to your website or app in a controlled, first-come-first-served order.
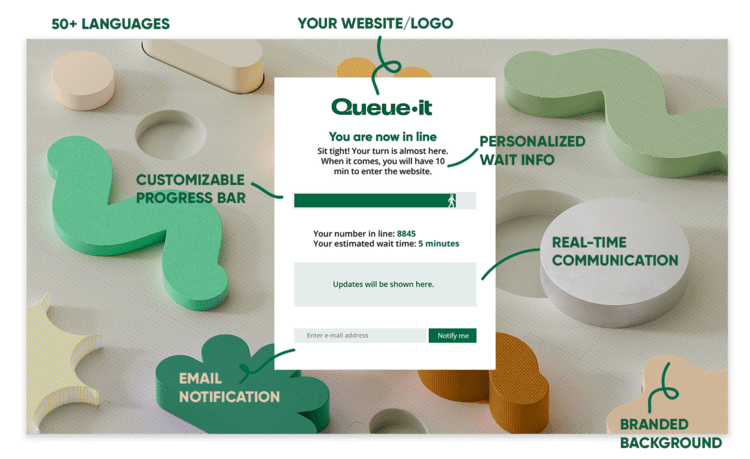
If you’re running a sale or registration that starts at a specific time, you can create a scheduled waiting room that will hold early visitors on a countdown page and then randomize them just like a raffle, giving everyone an equal chance. Visitors arriving afterwards are added to the end of the queue on a first-in-first-out basis.
A virtual waiting room allows you to:
- Ensure website performance: The virtual waiting room takes the spike in load from and lets you control the flow of customers into your site, ensuring you never exceed the technical capacity of your systems and can sell as fast as possible without crashing.
- Improve customer experience: Virtual waiting rooms replace the frustrating experience of a website crash or slowdown with transparent and controlled access, including detailed info on spot in line and estimated wait time on a branded page that can feature interactive elements like videos or games.
- Deliver fair access: In scenarios like limited-time offers or exclusive product launches, a virtual waiting room provides sophisticated fairness mechanisms like first-come-first-served access or live raffle randomization, ensuring all customers have a fair shot at your offer.
RELATED: The Comprehensive Guide to Virtual Waiting Rooms: All Your Questions Answered
“Queue-it’s virtual waiting room reacts instantaneously to our peaks before they impact the site experience. It lets us avoid creating a bunch of machines just to handle a 3-minute traffic peak, which saves us time and money.”
THIBAUD SIMOND, INFRASTRUCTURE MANAGER
Few blogs will tell you to downgrade your site’s user experience. But when you’re facing massive traffic, it’s an easy way to increase your capacity.
The issue with developments in website UX like dynamic search and personalized recommendations is they can be extremely performance intensive.
To prevent website crashes, it’s best practice to limit the number of fancy features and plugins you use on your site. These may look good and be useful, but they can quickly become outdated, and updates to them can cause major issues.
Well prepared ecommerce sites can toggle non-critical features like a recommendation engine on and off. They might be a nice touch for customers 95% of the time, but when you’re facing 10x traffic spikes on Black Friday, it’s better to have a simple site than functions than an advanced site that crashes.
As Bart De Water, manager at Shopify Payments team, says “A degraded service is better than [it] being completely down.” He explains Shopify has many ways it can pivot in the event of a failure of one of the systems it depends on. For example, if their in-memory data store (Redis) goes down, they can switch to present a logged-out view to users. This way, even though users can’t log in, they can still browse the store front, and are not met with a HTTP 500 error.
"A degraded service is better than it being completely down."
Try to identify non-essential plugins and performance-intensive processes and either temporarily remove them for big days or scale them back.
For example, rather than an advanced, CPU-heavy search function, you can use a simpler search function to free up the database for business-critical purposes.
RELATED: The Worst Advice We’ve Heard to Prevent Website Overload
The above steps are important to handle traffic as it reaches your site. But there’s also traffic you’ll want to keep off your site altogether. This unwanted traffic often comes in the form of bad bots or attacks on your website. Keeping these off your infrastructure is essential to mitigating downtime.
Distributed Denial-of-Service (DDoS) attacks, for instance, take down hundreds of sites and systems every year. They work by flooding a target server or network with massive amounts of malicious traffic. They’re called Denial-of-Service attacks because this massive flood of traffic can overwhelm servers, meaning regular users (your customers) are denied service.
DDoS attacks are getting cheaper and more common. These website hitmen are now available for hire for around $300. In the second half 2021, Microsoft mitigated over 359,713 unique DDoS attacks, a 43% increase from the first half of the year.
These attacks are often designed to expose vulnerabilities in a system or sabotage a company or organization. It’s no coincidence, for example, that over 70 Ukrainian government websites were taken down by an onslaught of DDoS attack in 2022.
Thankfully, most DDoS attacks are preventable with a web application firewall (WAF), which filters and blocks certain types of traffic to and from a web service. Your CDN should include a WAF that protects your site, but it’s worth double checking to make sure.
There’s another kind of bad traffic that’s harder to stop and can overwhelm your site in much the same way a DDoS attack does: online shopping bots.
How do online shopping bots crash websites? Let’s look at an example.
In 2022, a top 10 footwear brand dropped an exclusive line of sneakers. Traffic to the site soared. The sneakers sold out. Everything seemed to go according to plan. But behind the scenes, something was wrong.
When Queue-it ran a post-sale audit on this drop, we found up to 97% of the activity was non-human—clicks, visits, and requests from malicious bots designed to snatch up product to resell it at huge markups.
Of the 1.7 million visitors who tried to access the drop, fewer than 100,000 were playing by the rules.
This retailer had a virtual waiting room in place, meaning the traffic didn’t overwhelm the site and most of the bots were blocked. But retail bot attacks like this are becoming more and more common, increasing by 106% YoY in 2021. And for businesses without a virtual waiting room or a powerful bot mitigation solution, they’re taking websites offline on their biggest days.
Bad bots are responsible for a staggering 39% of all internet traffic. And during sales like limited-edition product drops and Black Friday or Cyber Monday sales, this number is much higher.
- 45% of online businesses said bot attacks resulted in more website and IT crashes in 2022.
- 33% of online businesses said bot attacks resulted in increased infrastructure costs.
- 32% of online businesses said bots increase operational and logistical bottlenecks.
While most businesses are concerned about high traffic caused by real users, many are unaware of the real risks and costs that come from bot, DDoS, and data center traffic.
Queue-it offers several tools to block bad bots and malicious traffic before it hits your site. These include:
- Data center blocking
- Server-side or Edge Connectors
- Proof-of-Work challenges
- CAPTCHA tests
- Queue tokens
- Invite-only waiting rooms that let you choose the users that get access to your site
RELATED: Everything You Need To Know To Prevent Online Shopping Bots
To err is human, which is probably why human error is the second most common reason for website crashes.
As capable and well-trained as your team may be, something at some point will go wrong. If human error can take down behemoths like Meta, it can take down your site too.
There are several important strategies to mitigating the risk of human error:
- Automated testing: Whatever can be automated, should be automated. Set up automated testing to run regular, consistent tests to validate the functionality, performance, and reliability of your site or service.
- Continuous deployment: Make small, incremental changes using continuous deployment. This is typically far safer than deploying major changes all at once.
- Procedures & best practices: Establish best practices and quality control measures for your team, such as code reviews and performance testing.
- Implement access controls & permissions: Limit access to critical functions to ensure that only authorized staff can make major changes or perform risky actions. This helps you avoid the meme of intern taking the website down.
- Conduct post-mortems: If something goes wrong, use it as a learning opportunity. Run post-mortems among teams that cover the contributing factors, potential countermeasures, and lessons learned—to prevent the same mistake being made twice.

An example of why permissions and access control is so important
We’ve covered a lot of ground in this blog. Individually, each of the above steps minimizes the risk of your website crashing for any reason. Together, they make a powerful crash prevention toolkit that’ll reduce your risk of crashes to close to zero.
If you’re committed to avoiding the cost of downtime and creating a website that stays online, no matter the demand, you’ll:
- Set up detailed, proactive monitoring to alert you to failures, help you understand your issues, and act on website overload before your customers even notice.
- Run performance and load tests to get a realistic understanding of how much traffic your site can handle and get the key info you need to boost capacity and improve performance.
- Identify and eliminate the bottlenecks that are limiting your site’s scalability.
- Optimize performance with simple tactics like using a CDN, compressing images, using lazy loading, and minimizing the use of plugins.
- Eliminate single points of failure by creating redundant systems that can spring into action and limit the damage of an outage.
- Configure autoscaling to give your site some flexibility in the amount of traffic it can handle and save you cloud computing costs on the quiet days.
- Manage traffic inflow using a virtual waiting room, to eliminate the risk of website crashes due to high traffic.
- Downgrade the user experience by scaling back or toggling off non-critical features on your big days.
- Block bad traffic and bots with a WAF that prevents DDoS attacks and a virtual waiting room or powerful bot mitigation tool that stops bots and data center traffic in its tracks.
- Improve & automate processes with tactics like automated testing, continuous deployment, procedures and training, post-mortems, and access controls.
If you need to act quickly to protect your site from surging traffic, a bolt-on tool like Queue-it's virtual waiting room is the fastest and simplest solution to preventing website crashes. Unlike these other tactics, you can get a waiting room up and running in less than a day, ensuring you stay online and serve every customer, no matter the demand.
Book a demo today and take control for your next high-profile product launch or sale.
“Queue-it’s a great bolt-on piece of infrastructure, completely dynamic to our needs. The virtual waiting room made much more sense than re-architecting our systems to try to deal with the insanity of product drops that take place a few times a year.”
TRISTAN WATSON, ENGINEERING MANAGER
(This blog has been updated since it was written in 2023.)