The 8 reasons why websites crash & 20+ site crash examples

Website crashes frustrate customers and cost companies millions in revenue, productivity, and brand reputation. And yet every year, dozens of major websites and service providers come crashing down. So why do websites crash? Why can’t massive companies with huge budgets seem to stay online? And what can be done to stop website crashes? Find out the answers to these questions and more in this blog and discover 20+ of the biggest website crash and outage examples of all time.
Websites crash for a variety of reasons, including network failure, human error, surges in traffic, and malicious attacks. Sites can be taken offline by everything from a viral social media post that overwhelms it with traffic, to a tired engineer who makes a mistake, to a natural disaster that cuts power to the site’s servers.
When a website crashes, it can’t transfer or receive data, meaning instead of the expected site content, visitors are met with an error code or blank page.
Site crashes affect everyone from small businesses to governments to retail giants. There is no “too big to fail” in the world of websites. Amazon, Apple, Facebook, the IRS, Google—they’ve all been taken offline for one reason or another.
Discover the 8 most common causes of website crashes, examples of sites that were affected by them, and the strategies you can use to prevent your site from crashing.
What causes websites to crash
- Network failure
- Website traffic surges
- Human error (broken/bad code)
- Plugin issues
- Update issues
- Expired domain names
- Malicious attacks & bots
- Third-party failures
RELATED: Everything You Need to Know About Website Crashes: Causes, Prevention & Examples
Network failure consistently tops IT surveys as the most common cause of downtime. Network issues are usually to blame when a massive company like Google, Facebook, or Amazon experiences site crashes or outages.
The network of a website or web application describes the distinct components it relies on to function, as well as the connections between them. Network failure typically occurs when one of these components fails, or, more commonly, when the connection and communication between two or more components fails.
Network failure can be something very simple, like an important cable being cut or disconnected or a router going offline. But it can also be quite complex, like when something goes wrong with the routing of traffic or data between a database and a web server.
You don’t need an in-depth understanding of networks or cloud computing to wrap your head around the problem of network failure. The rise in network failure taking sites and services offline is the result of the increasing complexity of these systems.
Think of modern networks like a smart home where you use a collection of apps, smart speakers, and switches to control your lights, security system, doorbell, windows, etc. Making your home “smart” may add convenience and security to your home, but it also adds a whole lot of complexity and connections to things that were once simpler and more distinct.
Gone are the days of flicking a switch and a signal going to your lightbulb. The functions of your home now rely on a complex range of software and hardware that must all work seamlessly together.
What if your smart speaker disconnects with your lightbulbs? What if your router goes offline? What if one piece of tech updates, briefly losing compatibility with another?
As in a smart home, there’s a tradeoff that’s made in all the recent advances in cloud computing and web hosting. Faster, more secure, more software-driven tech adds complexity and creates dependencies. It makes it not only crucial that the sperate components of a network function, but also that the connections between them function.
To put this complex problem very simply:
- Networks are more complex than they used to be.
- There are more distinct components that need to communicate with one another (thanks to the rise of micro-services).
- These components are more distributed geographically, making this communication more important.
- And to manage this more complex communication and geographical distribution, there’s more (and more complex) software powering this whole process.
It's added complexity on top of added complexity. And the more complex a network is, the more complex its failures become.
The more complex a network is, the more complex its failures become.Companies used to worry about network failure resulting from problems impacting hardware, such as extreme weather events or cable breaks. But today’s software-defined networks mainly deal with issues such as configuration errors, firmware errors, and corrupted routing tables (which are data tables that dictate where data is sent to in a network).
In 2022, Cloudflare rolled out a planned configuration change that involved adding a new layer of routing. The change was imperfect and ended up taking down some of the world’s biggest sites and services, including Amazon, Twitch, Steam, Coinbase, Telegram, Discord, DoorDash, Gitlab, and many more.

But Cloudflare is far from alone in suffering from network failure caused by configuration errors and routing problems. Other companies taken down by similar problems include:
- Meta and its subsidiaries (Facebook, WhatsApp, Instagram, etc.) were taken down for over 7 hours in 2021 after configuration changes were made to “the backbone routers that coordinate network traffic between our data centers.”
- Google and its subsidiaries (google.com, Gmail, Google Maps, etc.) crashed in 2019 after a configuration change affected the servers more than intended. “The network became congested, and our networking systems correctly triaged the traffic overload and dropped larger, less latency-sensitive traffic in order to preserve smaller latency-sensitive traffic flows, much as urgent packages may be couriered by bicycle through even the worst traffic jam,” the company said of the incident.
- Amazon Web Services experienced a partial outage in 2021 that affected Netflix, Disney+, Robinhood, Amazon.com, as well as Amazon’s Ring security cameras and robot vacuum cleaners. They explained the outage was related to network devices and linked to one of their APIs.
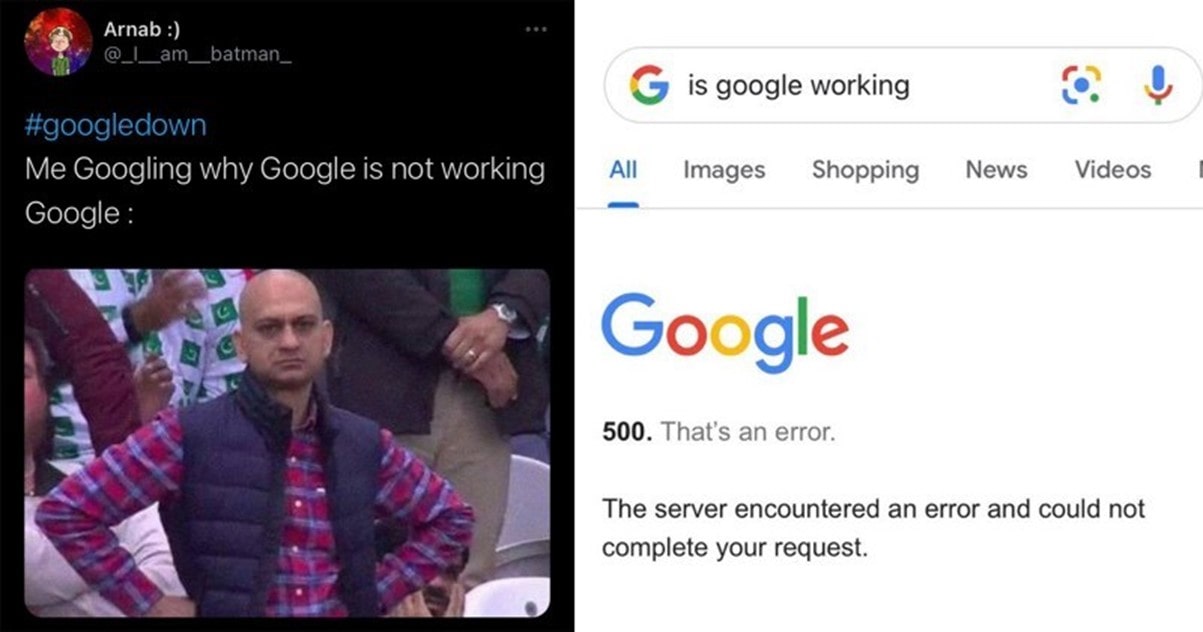
While web traffic spikes are the second biggest catalyst of website crashes, they’re by far the cruelest. There are two key reasons traffic-induced website crashes are so frustrating and costly for businesses and organizations:
- Web traffic spikes crash your site when you’re at your most visible (during Black Friday, a concert ticket sale, a product drop, etc.).
- Unlike network failure, web traffic spikes affect your business or organization in isolation, meaning your competitors remain online to poach your frustrated customers.
Website crashes from high traffic lose you the most business, have the biggest impact on your reputation, and are the most preventable.
So why do websites go down when they’re busy?
Surges in online traffic crash websites because traffic levels exceed the capacity of the website’s infrastructure. Site visitors create system requests—clicking buttons, adding products to carts, searching for products, inputting passwords—that exceed the processing capacity of your servers and/or any third-party systems involved in the visitor journey. When this happens, your website will slow down, freeze, or crash.
Simply put: websites crash because insufficient resources lead to system overload.
To learn more about how high online traffic and web traffic spikes crash websites, check out the video below, or our blog on the topic.
Companies like Ticketmaster, The North Face, and Zalando prevent website crashes caused by traffic spikes using a virtual waiting room.
Virtual waiting rooms work by automatically redirecting online visitors to a waiting room when they enter a protected part of the user journey, for example visiting a landing page or proceeding to checkout.
Customers are seamlessly flowed from the site to a branded waiting room like the one below, where they see their number in line, their estimated wait time, and a progress bar. From here, they're flowed back to your site at the rate it can handle in a fair, controlled order.
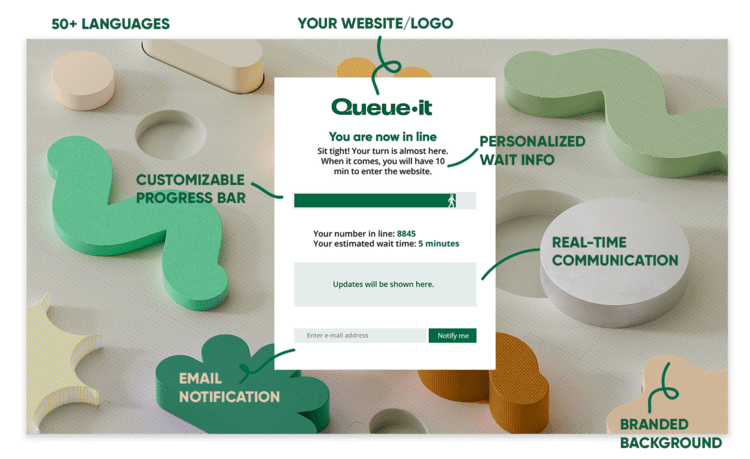
While brands often customize their waiting rooms both in style and in URL to look like the original site, the visitors in them are hosted on the virtual waiting room provider’s servers. This means no strain is placed on the target website’s servers while visitors wait for access.
“Queue-it’s virtual waiting room reacts instantaneously to our peaks before they impact the site experience. It lets us avoid creating a bunch of machines just to handle a 3-minute traffic peak, which saves us time and money.”
THIBAUD SIMOND, INFRASTRUCTURE MANAGER
- Amazon’s ecommerce store crashing on Prime Day in 2018.
- Coinbase’s site crashing from the traffic from its Super Bowl ad in 2021.
- Taylor Swift’s “Midnights” album crashing Spotify in 2022.
- Chipotle’s site and app crashing in 2018 after offering free guacamole with online orders on National Avocado Day.
- The U.S. Internal Revenue Service’s (IRS) site crashing and slowing down due to the last-minute tax time rush in 2018 and 2022.

Chipotle’s error page on National Avocado Day
Human error is the third most common cause of website crashes. These errors typically occur when new features, code changes, or updates are rolled out.
Most major websites are extremely complicated and the systems that enable them to function are highly interdependent. There’s a lot that goes on behind-the-scenes to ensure the average person has a fast and smooth user experience.
When a user buys something from an ecommerce site, for example, the database and servers must:
- Respond to the customers’ search and filter queries while they browse products.
- Check for inventory as they load product pages.
- Update the inventory in the database as they add item(s) to their cart.
- Verify their email and password as they login.
- Call on a third-party plugin or the database to autofill their address and pull tax information.
- Check their card details with the payment provider as they pay.
- Send out a confirmation email.
- Forward the information to the warehouse.
And this isn’t even the full picture—the site may also show personalized recommendations based on complex recommendation engines, run checks to prevent bots and fraud, and load video content and high-resolution images.
The point is: there’s a lot of software and hardware that supports these processes, meaning there’s a lot of room for error.
Even minor changes to a website, like changing an algorithm or implementing a new third-party plugin, can bring the site down. And it’s not just bad code that comes into play, human error can also come from misconfigurations between development environments, problems with permissions, or changes to infrastructure.
Of course, (good) developers test changes to ensure they function before pushing them to production (the live version of the site). But some errors still slip through the cracks, particularly those that only appear when the website is under heavy usage (these errors can be detected with load testing).
RELATED: How To Prevent Website Crashes in 10 Simple Steps
- The 7-hour crash of Meta and its subsidiaries (Messenger, Instagram, WhatsApp, etc.) was not only a network failure, it was also a human error. Meta explained the outage was caused by “a command issued by an engineer during a routine maintenance which unintentionally took down all the connections in our backbone network, effectively disconnecting Facebook data centers from the Internet globally.”
- Marks & Spencer’s £150 million website rebrand was rife with technical issues when it went live, forcing them to take the site offline for a period to fix them—resulting in an 8% drop in ecommerce sales for the period.
- The launch of healthcare.gov was involved one of the most public and damaging website crashes of all time. While it initially crashed due to high traffic, the site remained rife with technical issues when it went back online. A reported 250,000 people visited the site on the first day, with only 6 managing to complete applications by the day’s end.
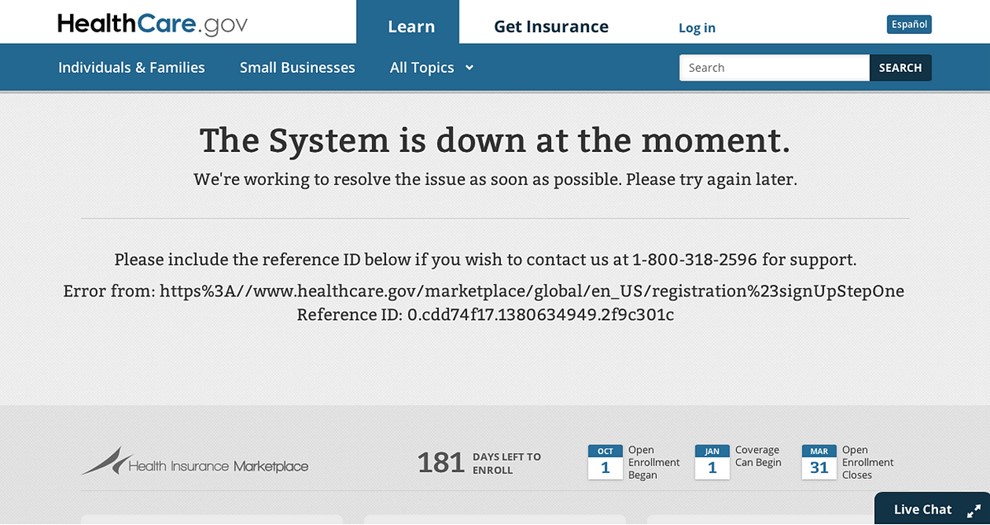
Healthcare.gov’s error page on the day it launched
Crashing a website or system by pushing changes to production is so common that “deploy to production” is a meme in programmer communities.
Plugins are pieces of software that add new features to a website/application. They do everything from helping with SEO and marketing to boosting security to adding forms to your site so you can capture email addresses.
The advantage of plugins is that they’re easy to use and quick to install (as the name indicates you can just “plug” them “in”). But adding plugins also invites risks to your site, including:
- Security vulnerabilities: Plugins can have security flaws that leave your website vulnerable to hacks and malicious attacks.
- Draining resources: Every plugin you add to your site brings with it an additional drain on your resources and adds complexity. Plugins can compete for computing power, leading to slowdowns and crashes.
- Conflicts: A well-running website should have all its components working in harmony. But some plugins can clash with a CMS, another plugin, or a key site feature. This can be particularly bad when a plugin you rely on is updated and causes issues, as you’re put in a “can’t live with it, can’t live without it” situation.
- Dependence on a third-party: It’s always smart to be careful who you (and your site) depend on. You want to ensure new plugins come from reliable and service-minded sources, so they don’t become outdated, and you can get support if something goes wrong.
Think of your website like a potluck dinner party, and the plugins as the guests.
You want to only invite the people you know and trust to avoid security issues. You want to keep the number of guests limited to avoid exceeding the capacity of your home. You don’t want to invite people you think will fight or clash with others at the party. And you want to ensure you can really rely on the people who say they’ll bring the main dishes, or you’ll end up with nothing to serve your visitors.
In short: each plugin you add—like each dinner guest—introduces new risk, complexity, and resource load.
Large companies rarely face issues with plugins. They often build solutions in-house and have teams of engineers who understand the risks of plugins and how to mitigate them.
But for websites run by small businesses on more non-technical platforms like WordPress and Shopify, plugin issues are so rampant that if you visit almost any forum where people complain about site crashes, the first advice is almost always to disable plugins.
One example of plugins bringing down sites occurred in 2018, when hackers discovered vulnerabilities in a popular WordPress plugin called WP GDPR Compliance. These vulnerabilities were quickly exploited, forcing many sites offline.
Plugins aren’t a bad thing. But it’s important you practice scrutiny and have a process before you go filling your site with them.
Ensure you use plugins that are popular and proven, test them before you add them to your site, backup your site before you deploy them, and commit to keeping them updated and testing each new update.

It’s important to keep your tech stack regularly updated to avoid technical issues and maintain performance. In some circumstances, failing to update your site can open it up to vulnerabilities and cause compatibility issues that result in it crashing.
But updating your site is almost as risky as failing to update it.
Change is necessary for improvement—no one updates things to make them worse—but change introduces risk.Change is necessary for improvement. But change introduces risk.
Things don’t always work as expected the first-time round. There are often issues that need to be ironed out or additional changes that need to be made.
As covered in point 3, most websites have many dependencies and need dozens of processes to work in harmony. Updates to internal or third-party software bring with them the risks of:
- Code & human error
- Conflicts and/or issues with compatibility
- Partial updates which cause compatibility issues
- New performance bottlenecks
It’s important to make regular updates if you want your system to improve. But it’s equally important to test these updates thoroughly if you want your site to stay online.
- A software update was to blame for a 2022 international outage of Google Search, Maps, Dive and YouTube. “We’re aware of a software update issue that occurred late this afternoon Pacific Time and briefly affected availability of Google search and Maps,” a Google spokesperson said. “We apologize for the inconvenience. We worked to quickly address the issue and our services are now back online.”
- A 2020 software update at Facebook temporarily broke the “login with Facebook” feature, rendering sites like Tinder, Spotify, and TikTok unusable.
- A 2021 software configuration update at Akamai caused a bug in its DNS system, taking down sites like Amazon, Delta, Capital One, and Costco.
- Not a website crash, but a crazy example of the dangers of untested software updates: When Dutch police updated the software behind their ankle monitors (for people on house arrest or on bail), 450 ankle monitors across the country crashed. The Dutch police and Ministry of Justice and Security had to act fast and take high-risk suspects from their homes to local jails, while house visits were made to lower-risk suspects.
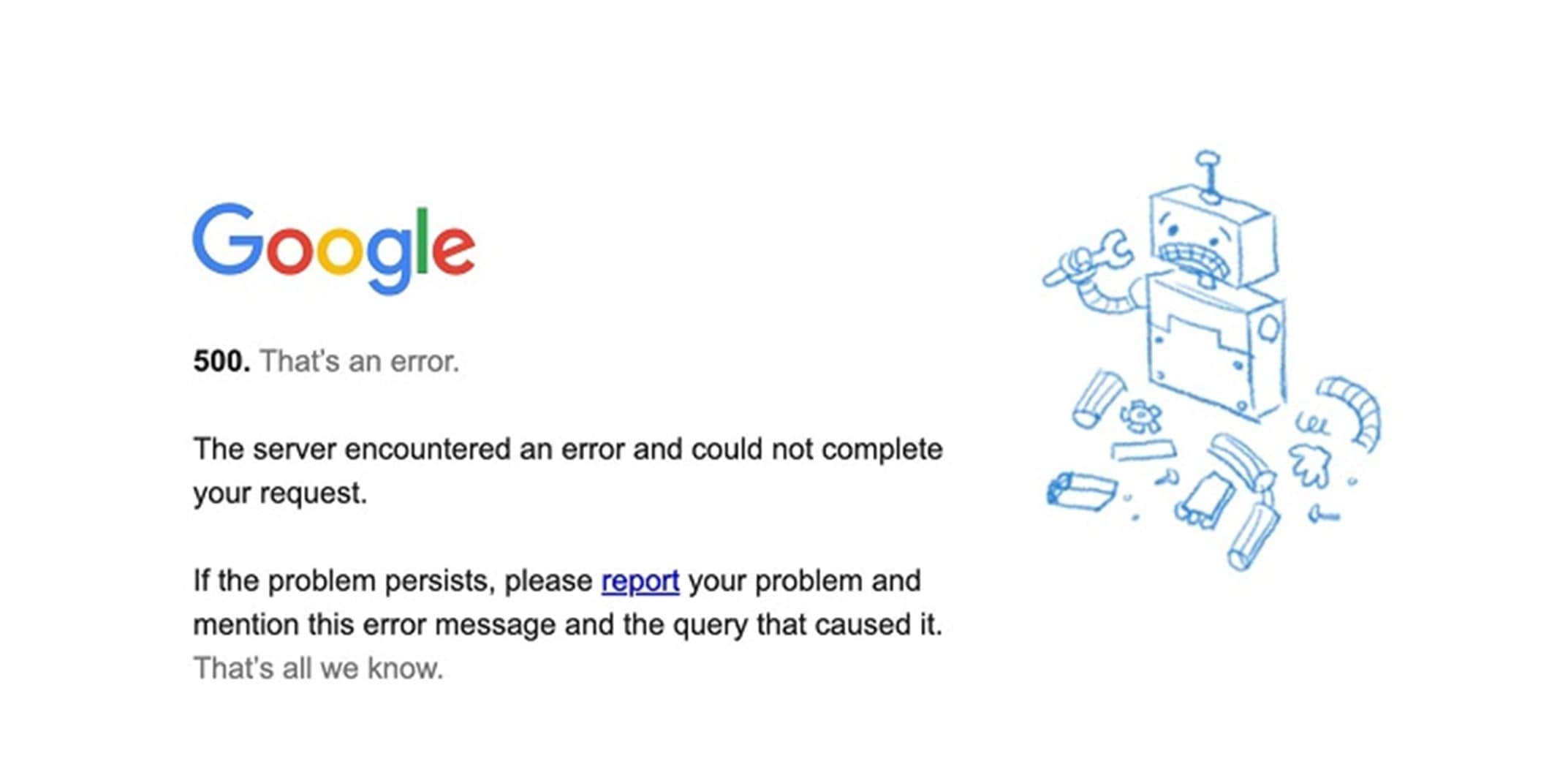
A rare 500 error page on Google.com during the 2022 outage
It may sound silly, but many websites crash when the site owner forgets to renew the domain name. Your domain name, or URL, is the address visitors use to access your website. It’s completely unique to your site and is essential if you want it to be accessible.
But domain names aren’t free. Site owners need to pay an annual fee to maintain their subscriptions. If they fail to renew it, they lose the domain and the site content disappears from the web. This can be easily prevented by auto-renewing your domain registration.
Unintentional domain name expiry happens less today than it used to, but it’s still a problem for sites that don’t auto-renew their domain.
- The Dallas Cowboys’ website went down on the day they fired their head coach. But it wasn’t the traffic from the news that caused the crash—they simply forgot to renew their domain name, leaving their site offline for several days.
- Microsoft forgot to renew the domain names of two of its websites (passport.com and hotmail.co.uk) in the late 90s and early 2000s.
- Foursquare.com had already received $10 million in funding when they forgot to renew their domain name and briefly lost their site.
- The 22nd largest bank in the U.S., Regions Bank, was down for almost a week while they fought to get their site back online after losing their domain name.
- Sorenson Communications domain name expiry cost them almost $3 million in fines, because their site was needed for critical services like 911 calls.
WhoAPI keeps an updated list of the most high-profile failures in domain name renewal here.

This is what foursquare.com looked like on the day of its domain name expiry (Source: WhoAPI)
Traffic to your website can be put into two basic categories: good and bad.
Good traffic includes the real people who visit your site because they’re interested in what it provides, as well as good bots like the Google bot—which ensures your site content appears in Google’s search results.
Bad traffic is just about everything else. Data center traffic, online shopping bot traffic, and malicious attacks. Bad traffic drives up infrastructure costs, spoils analytics, and can even bring down your website.
Distributed Denial-of-Service (DDoS) attacks, for instance, take down dozens of sites and systems every year. They work by flooding a target server or network with massive amounts of malicious traffic. They’re called Denial-of-Service attacks because this massive flood of traffic can overwhelm servers, meaning regular users (your customers) are denied service.
DDoS attacks are getting cheaper and more common. These website hitmen are now available for hire for around $300. In the second half 2021, Microsoft mitigated over 359,713 unique DDoS attacks, a 43% increase from the first half of the year.
These attacks are often designed to expose vulnerabilities in a system or sabotage a company or organization. It’s no coincidence, for example, that over 70 Ukrainian government websites were taken down by an onslaught of DDoS attack in 2022.
Thankfully, most DDoS attacks are preventable with a web application firewall (WAF), which filters and blocks certain types of traffic to and from a web service. Your CDN should include a WAF that protects your site, but it’s worth double checking to make sure.
- In 2022, over 800 Greek State websites were crashed and/or slowed by an unprecedented DDoS attack. TAXISnet, the Greek tax service, was taken offline for 48 hours.
- Canadian PM Justin Trudeau’s official website was taken offline in 2023 by DDoS attacks reportedly carried out by a pro-Russian threat group.
- One of the most famous internet outages of all time—that of Dyn in 2016—was caused by a massive DDoS attack. It took down high-profile websites including GitHub, HBO, Twitter, Reddit, PayPal, Netflix, and Airbnb.
- GitHub’s site crashed again after a huge DDoS attack in 2018.
- In 2000, a 15-year-old high schooler known as “MafiaBoy” took down the websites of CNN, Dell, eBay, and Yahoo! (then the biggest search engine in the world) with DDoS attacks.
There’s another kind of bad traffic that’s harder to stop and can overwhelm your site in much the same way a DDoS attack does: online shopping bots.
How do online shopping bots crash websites? Let’s look at an example.
In 2022, a top 10 footwear brand dropped an exclusive line of sneakers. Traffic to the site soared. The sneakers sold out. Everything seemed to go according to plan. But behind the scenes, something was wrong.
When Queue-it ran a post-sale audit on this drop, we found up to 97% of the activity was non-human—clicks, visits, and requests from malicious bots designed to snatch up product to resell it at huge markups.
Of the 1.7 million visitors who tried to access the drop, less than 100,000 were playing by the rules.
These shopping bots hit site in such massive volumes they were essentially running an unintentional DDoS attack—that is, smashing the site with more traffic than it can handle.
This retailer had a virtual waiting room in place, meaning the traffic didn’t overwhelm the site and most of the bots were blocked. But retail bot attacks like this are becoming more and more common, increasing by 106% YoY in 2021. And for businesses without a virtual waiting room or a powerful bot mitigation solution, they’re taking websites offline on their biggest days.
Bad bots are responsible for a staggering 39% of all internet traffic. And during sales like limited-edition product drops and Black Friday or Cyber Monday sales, this number is much higher.
- 45% of online businesses said bot attacks resulted in more website and IT crashes in 2022.
- 33% of online businesses said bot attacks resulted in increased infrastructure costs.
- 32% of online businesses said bots increase operational and logistical bottlenecks.
While most businesses are concerned about high traffic caused by real users, many are unaware of the real risks and costs that come from bot, DDoS, and data center traffic.
- Nike SNKRS app faced crashes and glitches during the 2022 release of the Air Jordan 1 “Lost and Found”—likely due to high bot traffic.
- Walmart’s site crashed several times when it launched the much-anticipated PS5s, with the company receiving over 20 million bot attempts throughout the day. For future releases, Walmart implemented a virtual waiting room to prevent crashes and filter the bot traffic.
- Shopping bots targeted vaccination registrations during the pandemic, crashing critical service providers’ websites across the globe.
- Strangelove Skateboards’ collaboration with Nike shut down their site after “raging botbarians at the gate broke in the back door and created a monumental mess for us this evening … Circumstances spun way, way out of control in the span of just two short minutes.”
RELATED: Everything You Need to Know About Preventing Online Shopping Bots

Strangelove Skateboards' Instagram apology after bots crashed their sneaker drop
Most websites rely on a wide range of third-party service providers to function. So when major cloud computing companies like Amazon, Cloudflare, or Google go down—typically from network failure—they take thousands of sites down with them.
There are two key reasons outages at major cloud computing companies cause so many websites to go down:
- It’s one of the few points of failure businesses and organizations have little to no control over.
- There’s a massive market concentration of just a few cloud service providers that serve as the “backbone of the internet”.
To stay online, most of the major websites and apps depend on one of three cloud infrastructure providers and one of three content delivery networks (CDNs). What this means is that if any of these providers has a large outage, for any reason, thousands of websites and potentially billions of site visitors are affected.
Three cloud infrastructure service providers—Amazon’s AWS, Microsoft’s Azure, and Google’s Google Cloud—control about 66% of the global cloud market. And the market concentration is even more pronounced for CDNs. The top three CDN providers—Cloudflare, AWS CloudFront, and Akamai—serve about 89% of all global CDN customers.
While these cloud giants are incredibly reliable, they’re not perfect. Parts of all their infrastructure have been taken down at one point or another by network failure, fires, storms, usage surges, or errors in updates.
Over a 3 month stretch in 2021, for example, Azure, Google Cloud, and AWS each had a major outage. Those 3 outages alone affected thousands of sites across the globe.
That’s why Amazon limits the size of its data centers—to limit the “blast radius” of destructive regional events. As Amazon’s CTO Werner Vogels says, “A data center is still a unit of failure. The larger you built your data centers, the larger the impact such a failure could have. We really like to keep the size of data centers to less than 100,000 servers per data center.”
Most website crashes are avoidable. But third-party failures are particularly difficult to prepare for because businesses and organizations can’t control what happens to the companies they rely on to keep their sites online.
These major cloud services are typically referred to as “the backbone of the internet”—and for good reason. If they go down, your site is likely to go down with them.
- A 2016 cyber-attack on DNS provider Dyn took out major websites including Amazon, Airbnb, BBC, CNN, Netflix, and Twitter.
- A 2021 outage at CDN provider Fastly crashed sites from Reddit to Amazon to The New York Times.
- A 2022 outage at AWS affected applications like Zoom and Webex.
- A 2023 outage of Google’s Cloud services caused by a water leak and fire took 90 Google Cloud services offline.
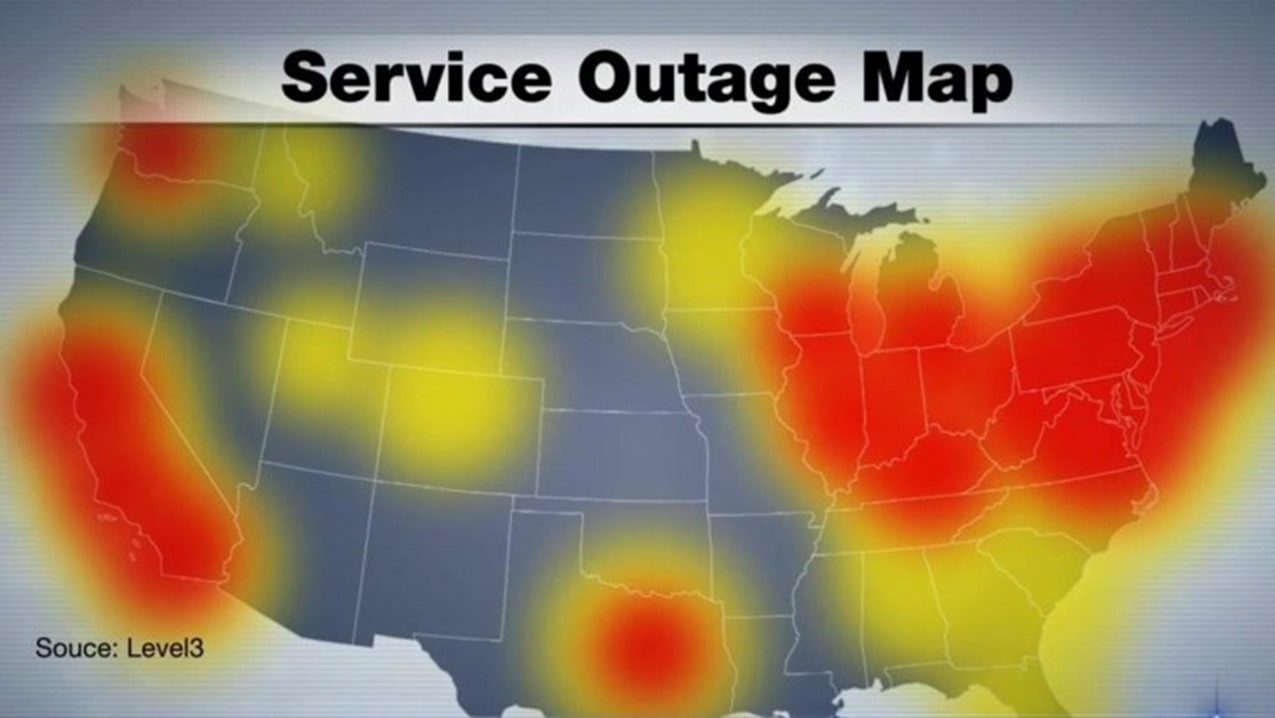
Map showing the areas of the U.S. affected by Dyn’s service outage in 2016 (source: NBC News)
As Sun Tzu said in The Art of War, “Know thy self, know thy enemy”. What applied to Chinese military strategies 2,000 years ago applies to website crashes today.
To prevent website crashes, you need a strong understanding of your website and how it functions (thy self), and a stronger understanding of the threats that can bring it crashing down (thy enemy).
The 8 reasons your site is most likely to crash are:
- Network failure: when one or more components of the network—or the connections between them—disconnect, fail, or become misconfigured.
- Web traffic spikes: when traffic levels exceed the capacity of the website’s infrastructure or overload key bottlenecks.
- Human & code errors: when bad, broken, or error-prone code changes are deployed to production.
- Plugin errors: when site plugins drain resources, create vulnerabilities, or cause conflicts.
- Update issues: When a site or software update causes issues due to poor testing, errors, partial updates, or conflicts.
- Expired domain names: when a site owner fails to renew their domain name.
- Malicious attacks & bots: when bad traffic overwhelms site infrastructure, either intentionally (as in the event of DDoS attacks) or unintentionally (as in the event of online shopping bot attacks).
- Third-party failures: when a third-party service a website depends on experiences an outage, bringing the site down with it.
Because websites crash for such a wide range of reasons, a comprehensive crash prevention plan involves many tactics and tools. You can learn about some of the most powerful of these tactics in our blog how to prevent website crashes in 10 simple steps. Or you can check out our dedicated blogs on crash prevention strategies like:
- Virtual waiting rooms: to handle web traffic spikes and protect against bad bots.
- Load testing: to prevent crashes due to high traffic and catch bad code.
- Online shopping bots prevention: to learn how you can stop bad bots before they hit your site.
(This blog has been updated since it was written in 2023.)