Everything you need to know about website crashes: Causes, prevention & examples

Everyone knows the pain of a website crash. But few know exactly what’s going on behind the scenes when a site fails. Discover everything you need to know about website crashes, including why websites crash, what you can do if you visit or own a crashed website, how much website crashes cost businesses and organizations, and what you can do to prevent website crashes.
Table of contents:
A website crash occurs when a website stops working as it should, preventing visitors from using or accessing it. Crashed websites can’t transfer or receive data, meaning instead of the expected site content, visitors are met with an error code or blank page. There are many reasons a website can crash—from traffic overload to code errors to cyberattacks.
Websites are hosted on servers. The job of these servers is to “serve” content to site visitors. But when these servers are overloaded, faulty, or taken offline for any reason, they cease to function—they can no longer serve content to visitors.
Instead, visitors are met with a 5xx error message (which means there’s a problem caused by the server). These include:
- 502 Bad Gateway error: the server is acting as a gateway (a middleman between the website visitor and another server) and received an invalid response from the upstream server.
- 503 Service Unavailable error: the server cannot handle the request.
- 504 Gateway Timeout error: the server is acting as a gateway and did not receive a response from the upstream server fast enough (the request timed out).

Website crashes impact companies and organizations of all sizes. You’d struggle to find any major website that hasn’t crashed at least once. Amazon, Apple, Facebook, the IRS, Google—they’ve all been taken offline for one reason or another.
- Coinbase Super Bowl ad: Coinbase’s 1 minute Super Bowl ad cost upwards of $10 million and caught the attention of millions across the U.S. The ad drove so much web traffic it crashed their site and app.
- Dyn cyberattack: One of the largest internet outages of all time occurred in 2016 after multiple distributed denial-of-service (DDoS) attacks targeted major Domain Name System (DNS) provider Dyn. This attack took down some of the world’s biggest sites and services, including Amazon, Reddit, PayPal, Netflix, Spotify, Visa, Tumblr, HBO, Shopify, and the Swedish Government.
- Twitter Oscar selfie: Remember the selfie below? Not only did the photo break the previous record for most retweeted photo, it also crashed Twitter

- Healthcare.gov: Obama's much-anticipated Healthcare.gov site crashed immediately after it launched, due to the influx of visitors. On the first day, over 250,000 people visited the site. And by the day's end, only six had successfully completed applications.
Websites crash for many reasons, including network failure, human error, surges in traffic, and malicious attacks. Websites can be taken offline by anything from a viral social media post that overwhelms the site with traffic, to a tired engineer who makes a mistake, to a natural disaster that cuts power to the site’s servers.
Common causes of website crashes include:
- Broken/bad code
- Plugin errors
- Issues with updates
- Server or hosting provider errors & outages
- Web traffic spikes
- Expired domain names
- Malicious cyberattacks
The three biggest culprits causing website crashes—according to LogicMonitor’s global survey of IT professionals—are network failure, traffic spikes, and human error. Let’s take a closer look at each.
Network failure consistently tops IT surveys as the most common cause of downtime.
The network of a website or web application describes the distinct components it relies on to function, as well as the connections between them. Network failure typically occurs when one of these components fails, or, more commonly, when the connection and communication between two or more components fails.
Network failure can be something very simple, like an important cable being cut or disconnected or a router going offline. But it can also be quite complex, like when something goes wrong with the routing of traffic or data between a database and a web server.
You don’t need an in-depth understanding of networks or cloud computing to wrap your head around the problem of network failure. The rise in network failure taking sites and services offline is the result of the increasing complexity of these systems.
Think of modern networks like a smart home where you use a collection of apps, smart speakers, and switches to control your lights, security system, doorbell, windows, etc. Making your home “smart” may add convenience and security to your home, but it also adds a whole lot of complexity and connections to things that were once simpler and more distinct.
Gone are the days of flicking a switch and a signal going to your lightbulb. The functions of your home now rely on a complex range of software and hardware that must all work seamlessly together.
What if your smart speaker disconnects with your lightbulbs? What if your router goes offline? What if one piece of tech updates, briefly losing compatibility with another?
As in a smart home, there’s a tradeoff that’s made in all the advancements to cloud computing and web hosting. Faster, more secure, more software-driven tech adds complexity and creates dependencies. It makes it not only crucial that the separate components of a network function, but also that the connections between them function.
To put this complex problem very simply:
- Networks are more complex than they used to be.
- There are more distinct components (microservices) that need to communicate with one another.
- These components are more distributed geographically, making this communication more important.
- And to manage this more complex communication and geographical distribution, there’s more (and more complex) software powering this whole process.
It's added complexity on top of added complexity. And the more complex a network is, the more complex its failures become.
The more complex a network is, the more complex its failures become
Companies used to worry about network failure resulting from problems impacting hardware, such as extreme weather events or cable breaks. But today’s software-defined networks mainly deal with issues such as configuration errors, firmware errors, and corrupted routing tables (which are data tables that dictate where data is sent to in a network).
In 2022, for example, Cloudflare rolled out a planned configuration change that involved adding a new layer of routing. The change was imperfect and ended up taking down some of the world’s biggest sites and services, including Amazon, Twitch, Steam, Coinbase, Telegram, Discord, DoorDash, Gitlab, and many more.

Cloudflare’s far from alone in suffering from network failure caused by configuration errors and routing problems. Other companies taken down by similar problems include:
- Meta and its subsidiaries (Facebook, WhatsApp, Instagram, etc.)
- Google and its subsidiaries (google.com, Gmail, Google Maps, etc.)
- Amazon Web Services (taking sites like Quora, Foursquare, and Reddit offline).
When IT professionals were asked how they avoid these issues, the overwhelming majority credited investment into their systems and training—meaning spending on developing expertise, building redundancy, monitoring, diagnostics, and improving recovery (many of which we’ll explore in more detail below).

While web traffic spikes are the second biggest catalyst of website crashes, they’re by far the cruelest. There are two key reasons traffic-induced website crashes are so frustrating and costly for businesses and organizations:
- Web traffic spikes crash your site when you’re at your most visible (during Black Friday, a concert ticket sale, a product launch, etc.).
- Unlike network failure, web traffic spikes affect your business or organization in isolation, meaning your competitors remain online to welcome your frustrated customers.
Website crashes due to high traffic lose you the most business, have the biggest impact on your reputation, and are the most preventable (we’ll get to how below).
So how do they happen?
Surges in online traffic crash websites because traffic levels exceed the capacity of the website’s infrastructure.
Site visitors create system requests—clicking buttons, adding products to carts, searching for products, inputting passwords—that exceed the processing capacity of your servers, databases, and/or any third-party systems involved in the visitor journey. When this happens, your website will slow down, freeze, or crash.
Simply put: websites crash because insufficient resources lead to system overload.
To learn more about how high online traffic and web traffic spikes crash websites, check out the video below, or our blog on the topic.
Human error is the third most common cause of website crashes. These typically occur when new features or updates are rolled out.
Most major websites are extremely complicated and the systems that enable them to function are highly interdependent. There’s a lot that goes on behind-the-scenes to ensure the average person has a fast and smooth user experience.
When a user buys something from an ecommerce site, for example, the database and servers must:
- Respond to the customers’ search and filter queries while they browse products.
- Check for inventory as they load product pages.
- Update the inventory in the database as they add item(s) to their cart.
- Verify their email and password as they login.
- Call on a third-party plugin or the database to autofill their address and pull tax information.
- Check their card details with the payment provider as they pay.
- Send out a confirmation email.
- Forward the information to the warehouse.
And this isn’t even the full picture—the site may also show personalized recommendations based on complex recommendation engines, running checks to prevent bots and fraud, and load video content and high-resolution images.
The point is: there’s a lot of software and hardware that supports these processes, meaning there’s a lot of room for error.
Even minor changes to a website, like changing an algorithm or implementing a new third-party plugin, can bring the site down. And it’s not just bad code, human error can also come from misconfigurations between different environments, problems with permissions, or changes to infrastructure.
Of course, (good) developers test these changes to ensure they function before pushing them to production (the live version of the site). But some errors still slip through the cracks, particularly those that only appear when the website is under heavy usage (these errors, as we’ll get to below, can be detected with load testing).
Crashing a website or system by pushing changes to production, is so common that “deploy to production” is a meme in programmer communities.
The video below—one of these memes—explains just one way human errors can cause crashes. (Note that the subtitles are not actually what the Spanish comedian El Risitas is saying but is a software engineer’s take on the meme format where Risitas’ words are replaced with a funny story).
RELATED: How to Avoid the Website Capacity Mistake Everyone Makes
Sometimes when a website looks like it’s crashed, it’s actually only down for you, the individual. If this is the case, the problem is likely with your computer, internet connection, or browser.
The easiest way to check whether this is the case is to visit a site like downdetector.com, put in the site URL, and check you aren’t the only one experiencing the error.
There could also be an issue with cached content stored on your computer. To check if this is the case, you can open the website in an incognito tab (cache is not stored in incognito). If the site works in incognito mode, you may need to clear the cache on your regular browser to use it. You can find out how to clear your browser cache here.
If the website is down, and you don’t need to make dynamic requests like logging in, purchasing an item, or viewing live information, you can access an archived or cached version of the crashed website.
Visit the Internet Archive and enter the URL into the Wayback Machine to access archived content that’s no longer live—although this will only work if someone has previously saved the page.
If the page isn’t available on the Wayback Machine, you can view Google’s cached version of the website. Cache is a form of storage that helps speed up the way you use the web and lessen the burden of your usage on the website’s servers. Think of it like a snapshot of the website—you can view it, but you can’t interact with it or change it.
To view Google’s cached content, simply add “cache:” to the beginning of the URL (e.g. cache:https://queue-it.com/blog/website-crash/).
If you’re trying to access a major company’s site and it’s crashed, you can be pretty confident they’re already well aware and frantically trying to get their site back online. But if the website is run by a small business, blogger, or hobbyist, they might be unaware the site has even gone down.
In these cases, your best bet is to reach out to them and inform them of the problem. Since their website is down, their social media channels or email will probably be the best way to get in touch.
Every company and organization should have a plan for what to do when their website crashes. Without a website crash recovery plan, your site will remain offline for longer, crash more often, and you’ll frustrate site visitors more than you need to.
Below is a high-level overview of what to do when your website crashes. For a more detailed explanation, check out our website crash recovery plan blog.
If your website or app has already crashed, the first thing to do is to determine if your system is under attack, and if so, mitigate any vulnerabilities. The only thing more important than getting your site back online is ensuring you don’t have a data breach or a loss or corruption of data.
How you can mitigate this risk depends on the type of attack and the system(s) affected. But typically, you need to isolate the system(s) accessed by the bad actors to prevent their attack from spreading. This could involve stopping the database or disconnecting breached user accounts.
After you contain the attack, you’ll need to eradicate it. Again, this depends on the type of attack, but it could involve blocking certain IP addresses or deleting affected files and restoring them from a backup.
The next step is to enact your escalation plans—meaning notifying the responsible people.
If you’re an online retailer, for example, you’d want to inform your internal IT, digital, and marketing departments. You might also call your hosting provider and any consultants or digital agencies you work with.
When time is literally money—downtime costs for 91% of enterprises exceed $300,000 per hour —you need to communicate quickly, clearly, and effectively to get your site back online. Many hands make for quick work, so don’t be shy—get the necessary people involved ASAP.
Not all website crashes are created equal. There are steps you can take to improve the experience of site visitors and mitigate the impact of the crash. Some ways you can minimize the damage include:
- Set-up a redirect to a simple landing page that apologizes and says “we’re working on it”
- Communicate the outage on social media and other channels.
- Put a halt to your advertisements and marketing campaigns (you don’t want to pay to send traffic to a broken site).
- Activate your virtual waiting room (if you have one) so you can give live updates to visitors and automatically redirect them back to your site when it’s back online.
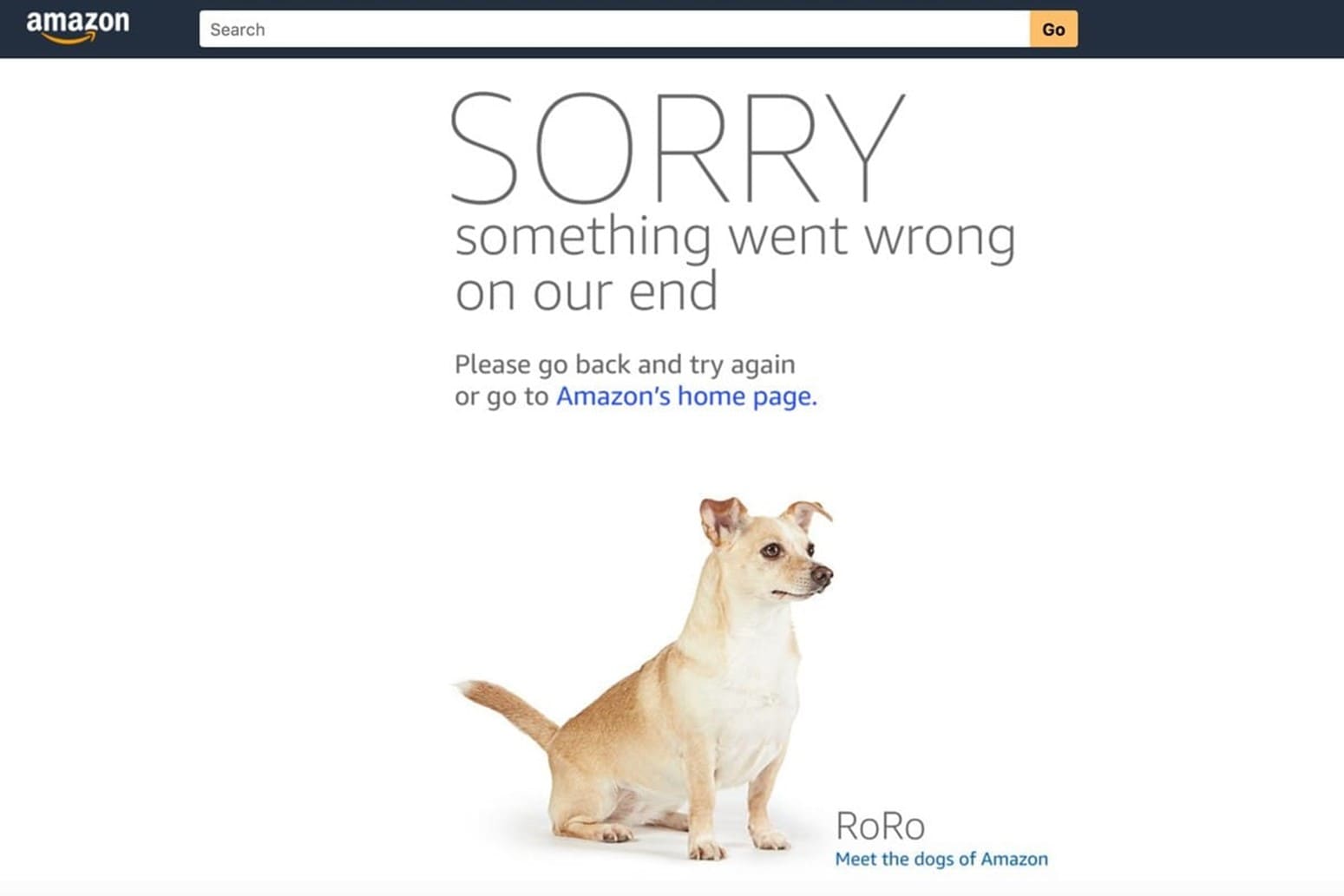
When Amazon crashed, they showed a page where they apologized and offered up photos of cute dogs.
When a major internet outage took out The Guardian and the Verge, for example, the news sites got inventive.
The Guardian ran a dedicated liveblog version of their news site on Twitter. And the Verge published their news on a shared Google Doc—which worked great until a reporter accidentally shared editing rights on Twitter and random internet users started having fun in the doc.
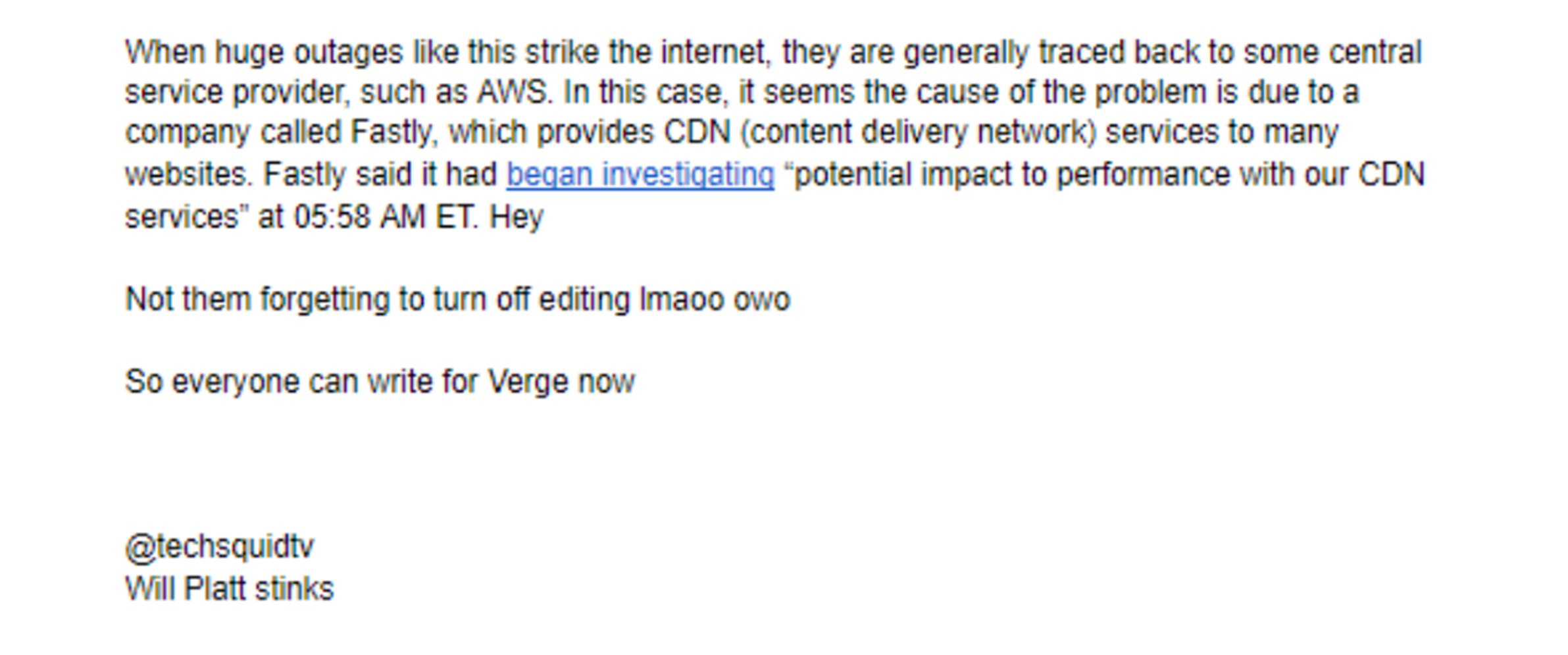
The Verge’s Google Docs news article, infiltrated by random internet users
How you get your site back online depends on why it crashed in the first place. Your team will need to diagnose and treat the root cause of the website crash.
Is it a code conflict with a new plugin you added to your site? Has traffic overwhelmed your payment and inventory bottlenecks, causing a cascading failure? If you have monitoring or logging set up, you’ll already be a step ahead in identifying the issue.
There’s no way to outline here exactly what steps you need to take, as that depends on many variables including your type of company, the root cause of the problem, your infrastructure setup, and what internal resources you have available. But we’ll get to how you can prevent it from happening again in the next section.
Once all these steps are done, you’re ready to communicate that your website is back up and running. But first, check a few things, especially if your website crashed because of overwhelming traffic:
- Ensure your site can handle the traffic (to avoid it crashing again for the same reason).
- Pre-load your cache before the system goes online (if you use a CDN).
- Write a public post-mortem statement explaining what happened and apologizing for the incident.
RELATED: Website Crashing? Here’s Your Recovery Plan Essentials
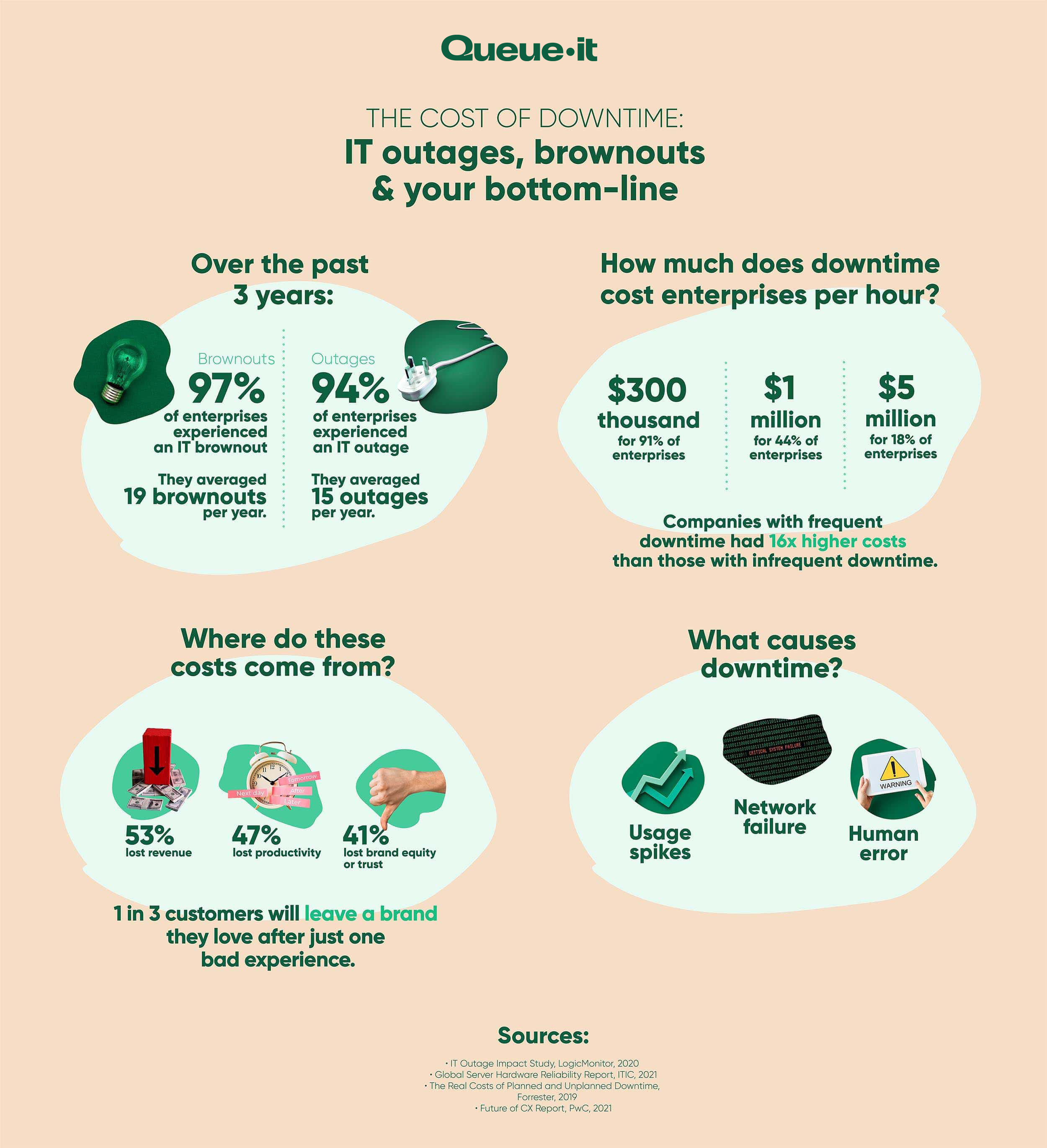
How much a website crash costs a business or organization depends on a wide range of factors. But all the numbers you can find on downtime tells one simple story: avoid it at all costs.
- Costs are up to 16x higher for companies that have frequent outages and brownouts compared with companies who have fewer instances of downtime.
- 91% of enterprises report downtime costs exceeding $300,000 per hour.
- The average cost of downtime is $54,000 per hour.
- For small-to-medium sized businesses, hourly costs are between $8,000 and $25,000.
You can find more information on the full costs of a website crash in our Cost of Downtime blog. But to put some of the numbers into concrete terms, here’s an example of how much an hour of downtime could cost a medium-sized business on one of their big sales days.
Say you’re a large retail site running a Black Friday sale. You have 1,000 visitors per minute, an average order value of $20, and a 5% conversion rate. This would give you an hourly visitor count of 60,000, and an hourly revenue stream of $60,000 during the sale. To keep things simple, let’s say your site crashes for exactly one hour. That means:
- $60,000 in lost revenue.
- 36,000 customers (60%) who are unlikely to return to your site.
- 20,000 customers (33%) who won’t return to your site.
- 39,000 customers (65%) who have less trust in your business than before.
There are several tools and tactics you can implement to dramatically reduce the risk of your site crashing. Just about every big company with an online presence leverages some combination of these tools to boost their reliability.
The following video runs through 6 steps you can take today prevent website crashes. For more detailed info (and one bonus step) continue reading through the points below.
Proactive monitoring won’t prevent website overload, but it’ll alert you before it happens and give you a good shot at preventing it.
A massive 74% of global IT teams rely on proactive monitoring to detect and mitigate outages. LogicMonitor found IT teams with proactive monitoring endured the fewest outages of all those surveyed.
Proactive monitoring alerts you to failures in real time and provides insights into your traffic levels and overall site performance.
And if your website does go offline, monitoring is key to conducting a root cause analysis and determining what went wrong. An accurate understanding of the root failure will allow you to optimize your system and prevent the same issue from occurring again.
Why are modern airplanes built with 4 engines when they typically only need one to fly? Because an airplane crash is an avoid-at-all-cost problem. Extra engines are just one of many redundant systems airplanes are built with, so that if any system fails in-flight, another can take over and the plane can maintain functionality.
If you’re serious about preventing website crashes, you need to think about your website in the same way. You need to eliminate single points of failure (SPOF).
To identify SPOFs, think of the services your website couldn’t run without (cloud hosting, payment providers, data centers, etc..). These are your airplane engines. To eliminate these SPOFs, you need to build additional redundant engines. This could involve:
- Having multiple, distributed data centers to avoid going totally offline or losing access.
- Establishing second payment service provider to switch to in the event of payment gateway failure.
- Using server clustering technology to run a duplicate copy of the application on a second server.
- Ensuring you have redundant hardware, such as additional cable connections that can be used in the event of a cable break.
While this is an expensive process, it’ll help you pivot quickly if one crucial part of your system dependencies fails. It’s also one of the only ways you can prevent crashes due to network failure.
As Bart De Water, manager at Shopify Payments team, says “A degraded service is better than [it] being completely down.”
He explains Shopify has many ways it can pivot in the event of a failure of one of the systems it depends on. For example, if their in-memory data store (Redis) goes down, they can switch to present a logged-out view to users. This way, even though users can’t log in, they can still browse the store front, and are not met with a HTTP 500 error.
“A degraded service is better than [it] being completely down.”
As Queue-it works with major companies on website crash prevention, high availability is a top priority. To avoid SPOFs, each region we have data centers in has 3 availability zones. Think of these like having 3 engines. In the (unlikely) event of a failure in two availability zones, Queue-it can still operate on the third.
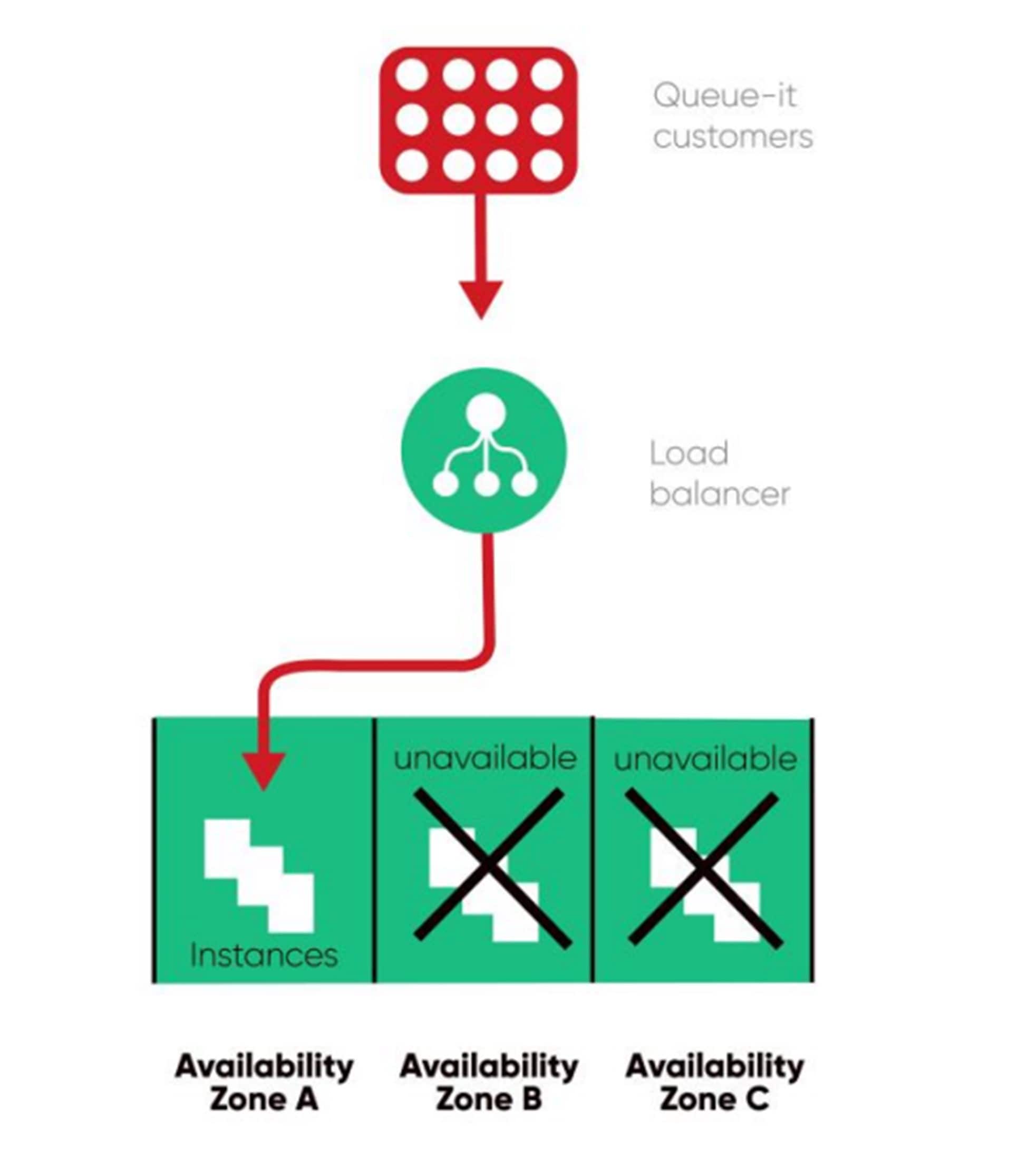
This is just one of many ways we value improving availability and reliability over reducing operational costs at Queue-it. You can learn more about how Queue-it ensures extremely high availability in our High Availability Whitepaper.
Load testing involves testing software’s performance with a specified load to understand how it behaves under expected or heavy usage. It’s a type of performance test that investigates the speed, scalability, and reliability of a system.
If you know your system works, load testing asks the question: “does it work at scale?”
Load testing is essential for preventing two of the top three causes of downtime: human error, and usage spikes.
- It prevents crashes due to human error because it reveals issues with software updates and code changes that may only occur under load.
- It prevents website crashes due to high traffic by simulating the expected traffic in a test environment to reveal whether your site and servers can handle it.
Load testing lets you understand the limitations of your system so you can improve its speed and reliability. It gives insight into performance issues and bottlenecks in a test environment, so your users don’t have to suffer through them in real life.
You can learn more about load testing in our comprehensive guide to load testing, but here are a few key stats that show just how important performance and load tests are:
- 92% of IT professionals say that performance and/or load tests are important or very important.
- 63% of enterprise IT leaders execute performance tests on all new releases.
- 57% of organizations run performance and/or load tests at every sprint.
- 95% commit to performance/load testing annually.
Load testing will point you toward your website’s weak spots. But to get any actual benefit and prevent website crashes, you’ll need to remove these bottlenecks and optimize your website performance.
Common ecommerce site bottlenecks you may want to investigate and optimize, for instance, include:
- Payment gateways
- Database locks & queries (e.g. logins, updating inventory databases)
- Building cart objects (add to cart or checkout processes, tax calculation services, address autofill)
- Third-party service providers (authentication services, fraud services)
- Site plugins
- Transactions (e.g. updating inventory databases while processing orders and payments)
- Dynamic content (e.g., recommendation engines, dynamic search & filters)
- CPU usage
Depending on your system and site set-up, the performance optimization process could involve many things. But essentially, you want to identify heavy database requests and limit their number, size, and complexity. There are many ways to build performance into your website. Some tactics include:
- Use a content distribution network (CDN), which responds to browser requests for your static content, like your home page and product images. This frees up your servers to focus on dynamic content, like your Add to Cart calls and checkout flows.
- Compress images and upload them at their intended display size. Use lazy loading to load media on demand, rather than all at once. Visitors perceive sites that load this way as faster, even if the actual load times are comparatively slow.
- Minimize the use of plugins where possible. They can quickly become out of date, and may not always maintain compatibility with your CMS or ecommerce platform.
RELATED: Optimize Your Website Performance with These 11 Expert Tips
Autoscaling is critical for any business dealing with fluctuating traffic levels. It enables your servers to automatically adjust their computing power based on current load.
With autoscaling, your server capacity can temporarily expand and shrink according to your needs. This reduces the need to make precise traffic predictions and makes your system more elastic and reactive.
Autoscaling saves money on the quiet days. And preserves performance on the big ones.
Or at least that’s the hope.
While this is what autoscaling does, it’s a bit more complicated than that. And as anyone who hosts a high traffic website knows, autoscaling isn’t the “cure-all” it sounds like.
RELATED: Autoscaling Explained: Why Scaling Your Site is So Hard
Autoscaling has several limitations when it comes to sudden traffic spikes:
- Autoscaling is reactive, meaning it can take too long to scale in response to load.
- Autoscaling doesn’t address common bottlenecks like payment gateways and database queries.
- If the application hasn't been purpose built for autoscaling, it may not have the elasticity required to autoscale for sudden traffic spikes.
The video below explains in simple terms what autoscaling is, why it’s important, and why it hasn't made website crashes a thing of the past.
The shortcomings of autoscaling are less about the capacity of website servers, and more about the on-site behavior of customers. So when autoscaling isn’t enough, the solution is to manage and control the traffic.
What do brick-and-mortar stores do when capacity is reached? How do physical venues deal with bottlenecks like ticket and ID checking? How do department stores deal with thousands of Black Friday customers trying to get into their store at once?
In all these scenarios, the flow of visitors is managed with a queue.
The same principle applies to your website. You can prevent website overload by controlling the flow of visitors into your site. And you can control the flow of visitors into your site with a virtual waiting room.
With a virtual waiting room, you can keep visitor levels where your site or app performs best. This ensures your overall capacity isn’t exceeded, but more importantly, it ensures the distribution of traffic to avoid overwhelming your bottlenecks.
A virtual waiting room manages and controls what none of the other steps on this list can: the flow of customers.
A virtual waiting room manages and controls what none of the other steps on this list can: the flow of customers.
Managing the inflow and distribution of traffic allows you to protect your bottlenecks and keep visitor levels where your site or app performs best.
What’s more, a virtual waiting room ensures a fair and transparent wait, and can actually boost conversion rates by tapping into social proof and anticipation psychology.
RELATED: What is a virtual waiting room?
We know you’ve worked hard on your website design and the user experience it provides. But when you’re facing massive traffic, fancy additions to your site can actually hinder its performance.
The issue with site additions like dynamic search and personalized recommendations is they can be extremely performance intensive. And the more complex these features are, the more likely they are to become bottlenecks as you scale to meet rising traffic levels.
Well prepared ecommerce sites can toggle these non-critical features on and off. They might be a nice touch for customers 95% of the time. But when you’re facing 10x traffic spikes on Black Friday, it’s better to have a simple site than functions than an advanced site that crashes.
It’s better to have a simple site than functions than an advanced site that crashes.
Try to identify performance intensive processes and either temporarily remove them for big days or scale them back.
For example, rather than an advanced, CPU-heavy search function, you can use a simpler search function to free up the database for business-critical purposes.
- A website crash occurs when a website stops working as it should, preventing visitors from using or accessing it. There are many reasons a website can crash—from traffic overload to code errors to cyber-attacks.
- Websites crash due to:
- Broken/bad code
- Plugin errors
- Issues with updates
- Server or hosting provider errors & outages
- Web traffic spikes
- Expired domain names
- Malicious cyber attacks
- Websites commonly crash during high traffic sales and registrations or when system updates or changes go live.
- If you’re a user visiting a website that’s crashed, you should:
- Check it’s not just you experiencing the crash
- Look for a cached or archived version of the site
- Contact the site owner
- If you’re a website owner with a crashed site, you should:
- Check for safety issues
- Implement escalation plans
- Limit the damage
- Resolve the issue
- Communicate the fix
- Website crashes cost businesses massive amounts of revenue and break down customer satisfaction and trust. Costs for companies that crash frequently are 16x higher than for those who have few instances of downtime.
- How can you prevent website crashes?
- Embrace detailed, proactive monitoring
- Eliminate single points of failure
- Run load tests regularly
- Optimize performance & remove bottlenecks
- Configure autoscaling
- Control traffic inflow with a virtual waiting room
- Downgrade the user experience with feature toggling